Curves Endpoint
The typical Curve endpoint follows this pattern:
https://splinecloud.com/
api/curves/<curve_uid>
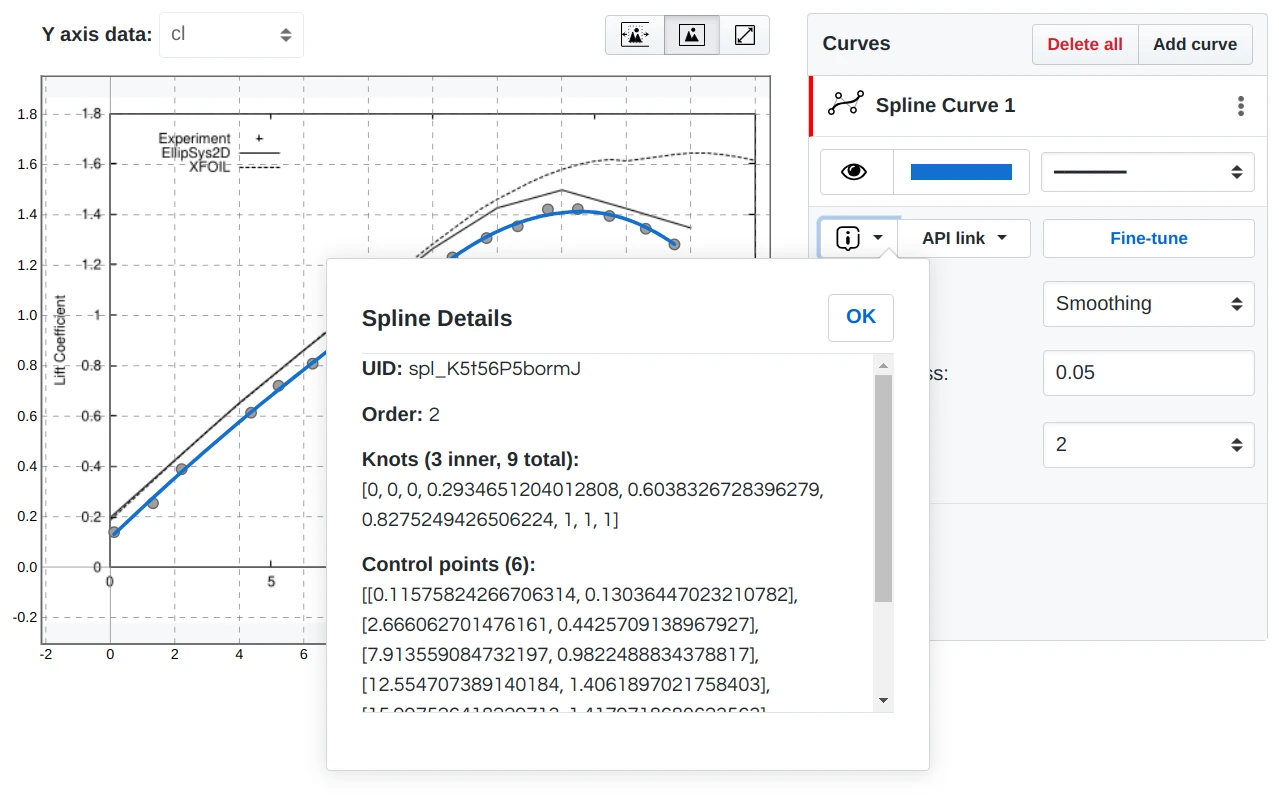
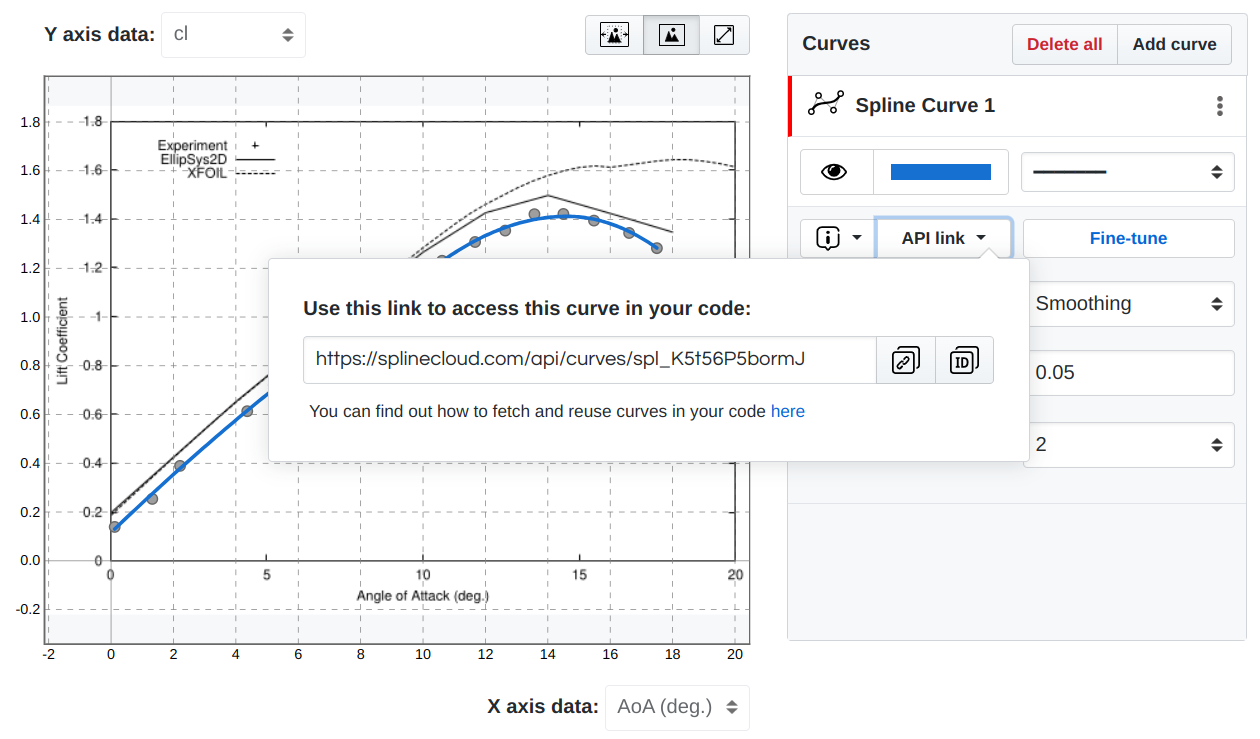
where <curve_uid> is a unique identifier of the curve, which can be found on the
API link drop-down window on the Curves toolbar.
Any spline curve (NURBS curve) is represented by the next parameters:
- order, k: integer
- knot vector, t: array of the float type numbers
- control points, c: array of the pairs of the float type
- weights of control points, w: array of integers
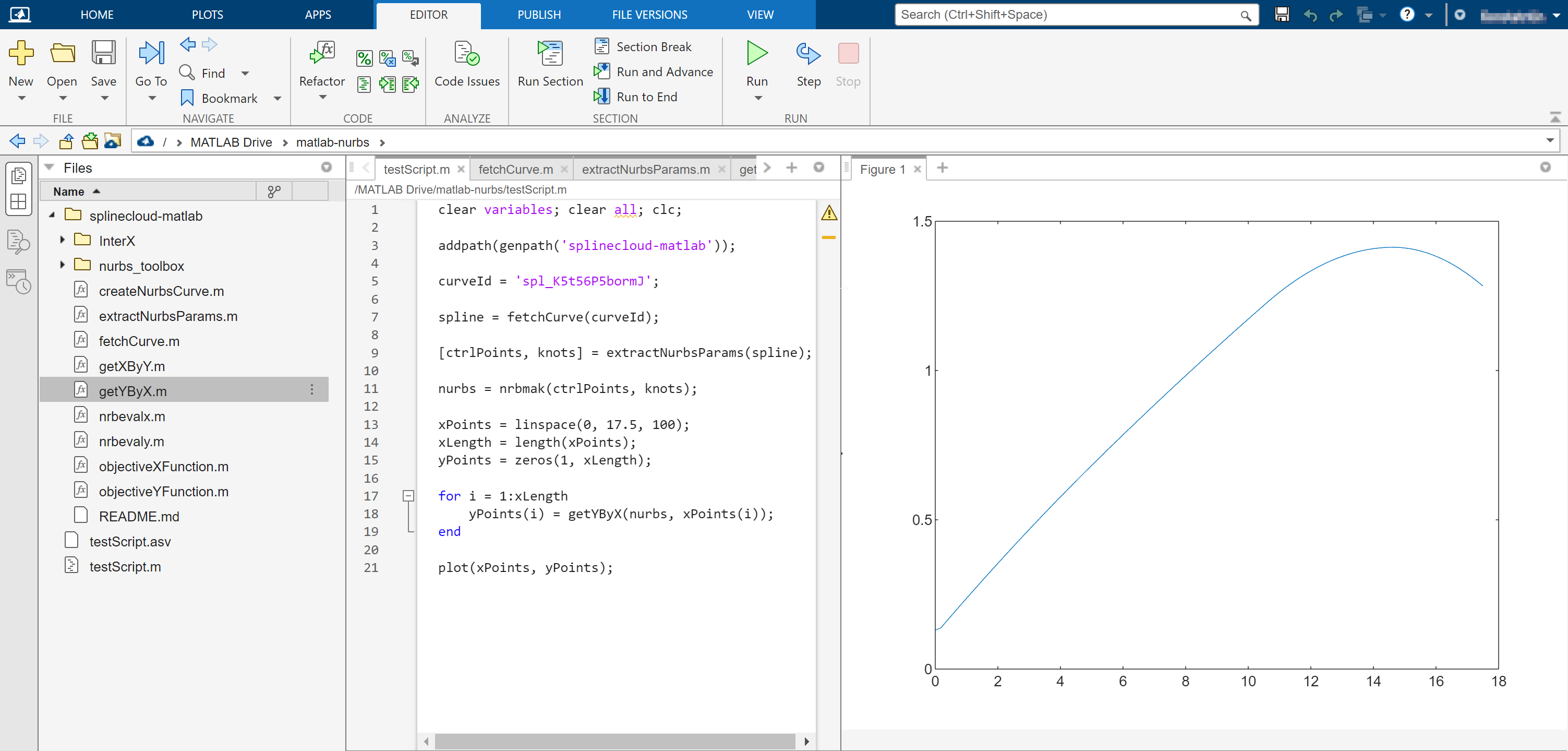
curl https://splinecloud.com/api/curves/spl_K5t56P5bormJ/
{
"uid": "spl_K5t56P5bormJ",
"name": "Spline Curve 1",
"curve_type": "smooth-bspl",
"order": 2,
"spline": {
"c": [
[
0.11575824266706314,
0.13036447023210782
],
[
2.666062701476161,
0.4425709138967927
],
[
7.913559084732197,
0.9822488834378817
],
[
12.554707389140184,
1.4061897021758403
],
[
15.997526418229713,
1.4179718680623563
],
[
17.496389067358194,
1.2830615476024234
]
],
"k": 2,
"t": [
0.0,
0.0,
0.0,
0.2934651204012808,
0.6038326728396279,
0.8275249426506224,
1.0,
1.0,
1.0
],
"w": [
1,
1,
1,
1,
1,
1
]
},
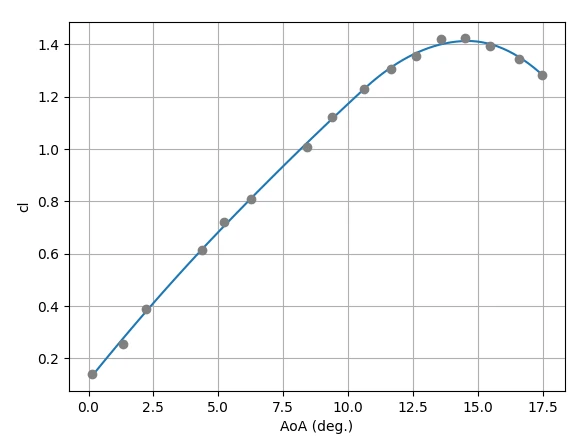
"labels": {
"xlabel": "AoA (deg.)",
"ylabel": "cl"
},
"relation_uid": "drl_788FVjNujErE",
"subset_uid": "sbt_iu0hd3vEvQpd"
}
The same parameters are also available in a curve details drop-down window.
.