SplineCloud’s approach to open and FAIR data
There exist a number of platforms for open science, including Open Science Framework, Zenodo, Figshare and others. However, SplineCloud goes beyond just offering a common space to share research outputs. With a heavy accent on reusability SplineCloud provides a set of tools to work with data and gives the ability to assign valuable attributes, making data easier to find and understand.
Data processing tools
SplineCloud provides free tools for data capture and data processing, that reduce the need to seek specialized instruments and hustle with transferring results. With SplineCloud you can work with data in common formats (spreadsheets, csv, text) and digitize image plots. The interactive curve fitting tool allows you to find the best fit to data in one click, fine-tune curves in advanced mode and reuse them in your code.
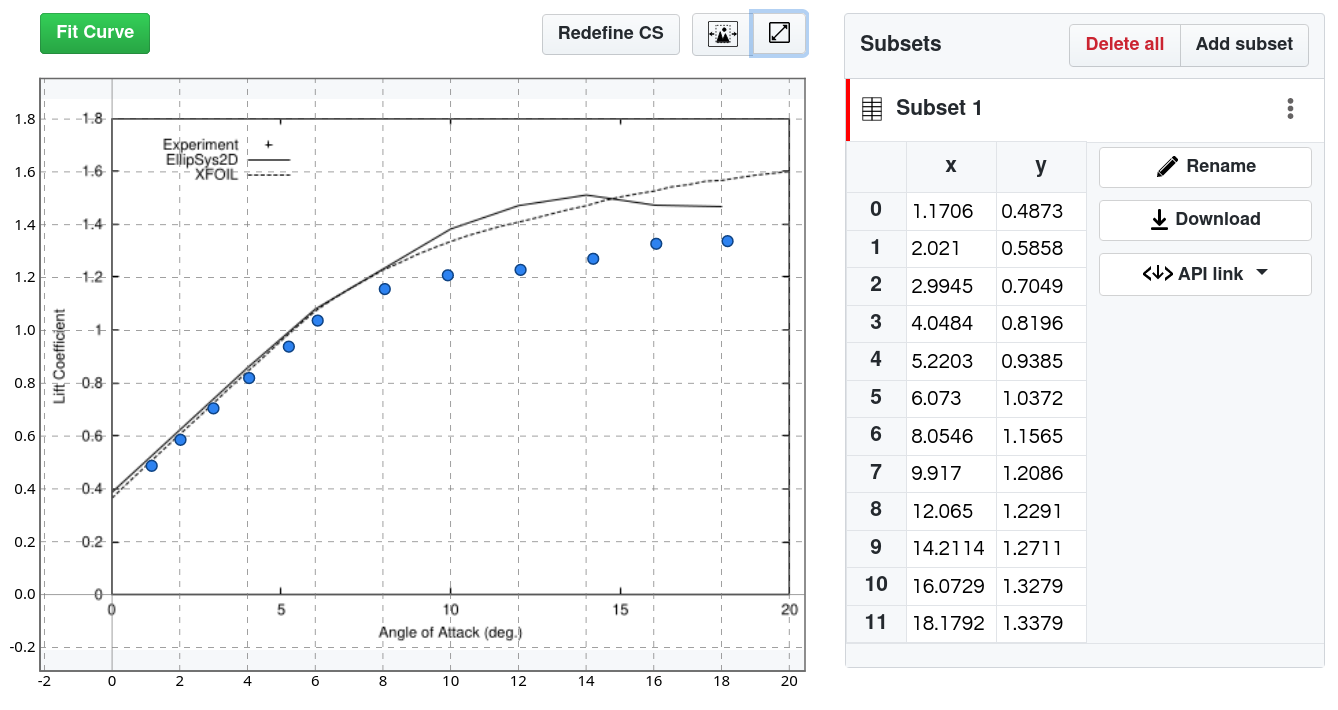
Plot Digitizing
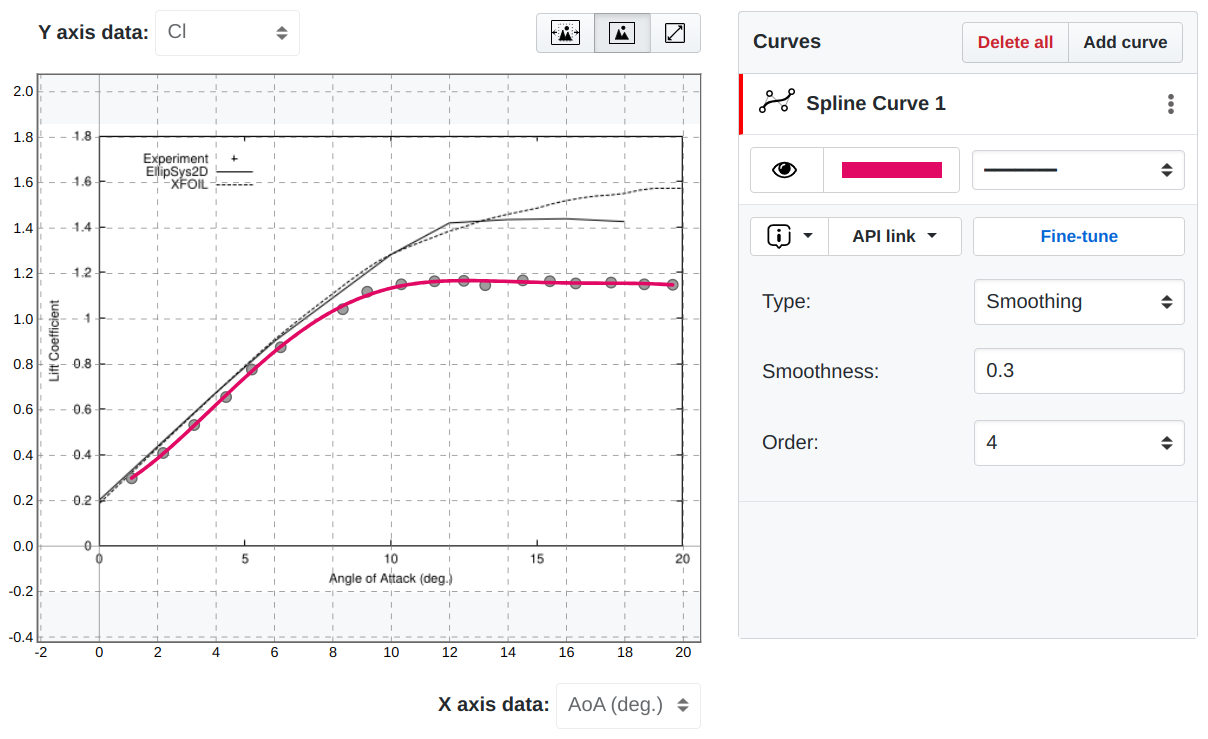
Curve Fitting
Simple repository structure
Basically, your data repository is just a cloud directory. You can create a folder structure and populate it with your data sources, after which you can start working with it, creating datasets and relations. SplineCloud allows you to upload and work with spreadsheets, text data, and scanned or captured image plots.
Creating New Repository
Description and topics
A short repository description and a number of topics, associated with your repository allow others to find your data on SplineCloud and discover similar data.
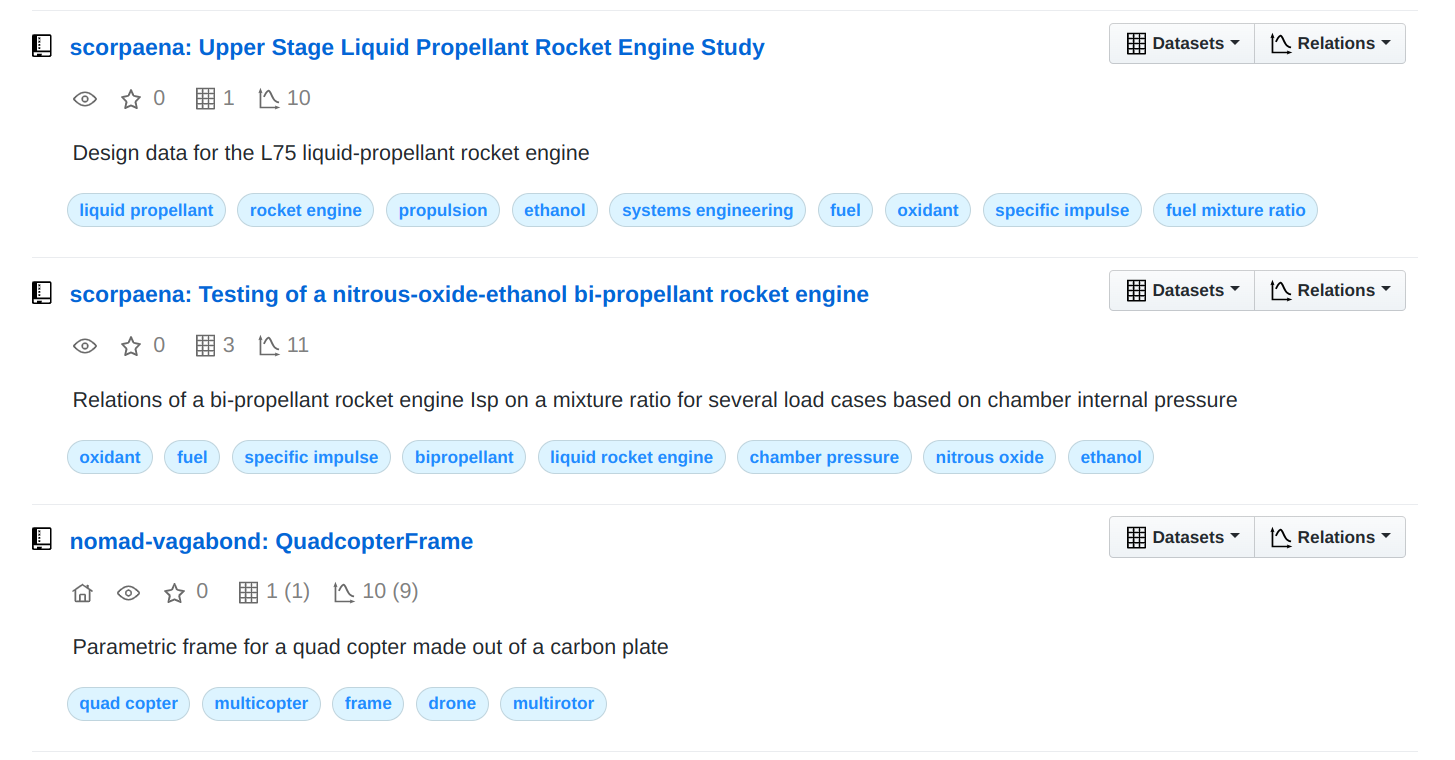
Repositories with Description and Topics
Wiki
In order to allow for a more comprehensive description of your data SplineCloud provides a Wiki section. Describe your methods and add references here so that others can have a detailed picture of the approaches and sources that have led you to the results of your study.
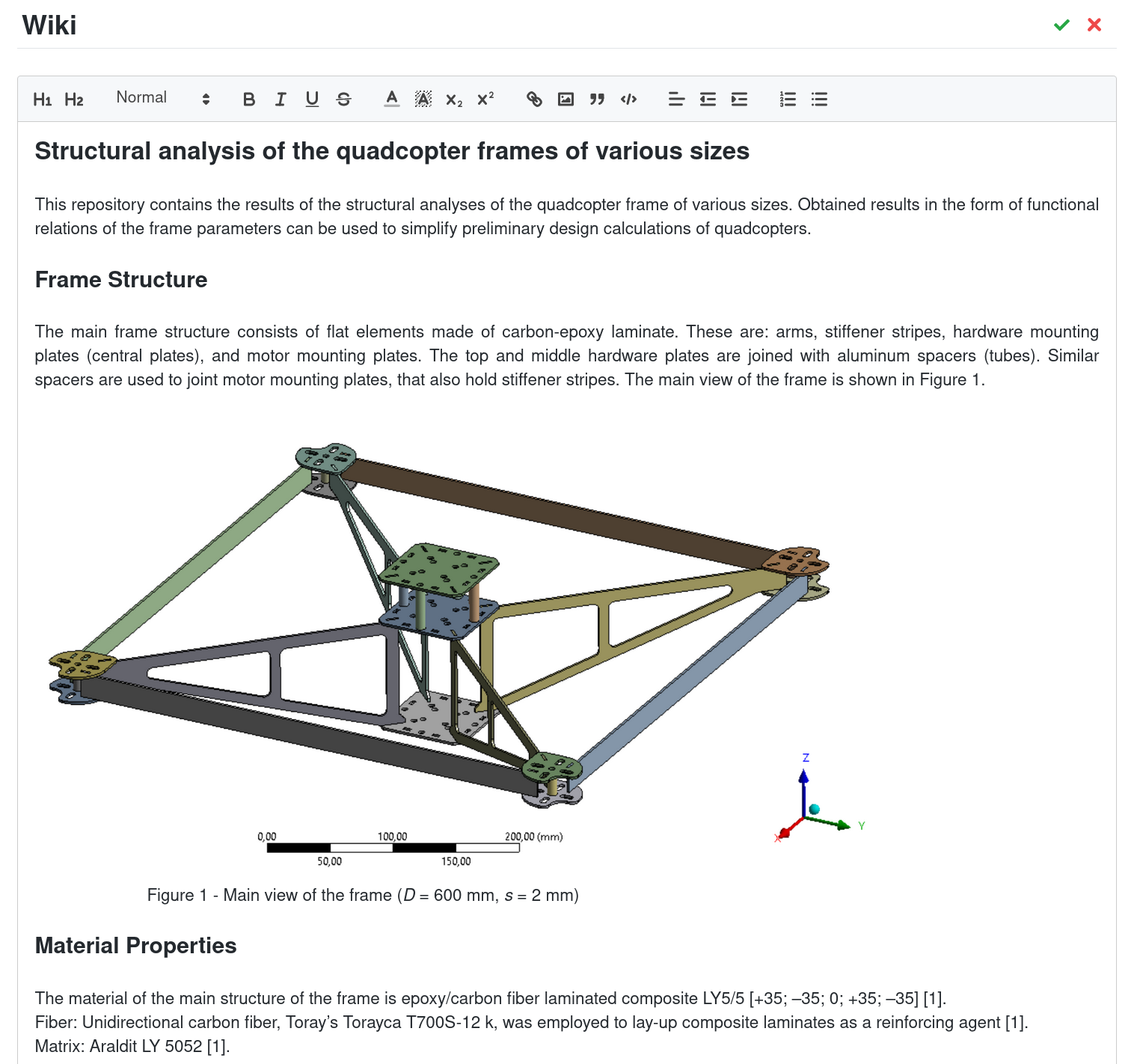
Editing Wiki Section
Stars
Simple, but verified approach of attributing your research, gaining feedback and improving the ranking of your repository.
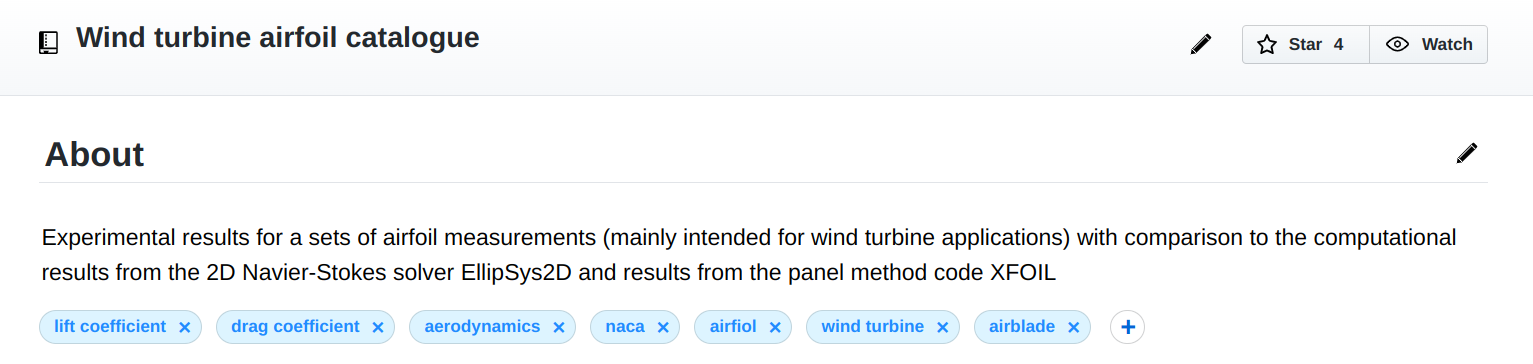
Repository Attributes and Stars
Datasets
SplineCloud automatically parses your spreadsheets and creates a dataset for each sheet. If your data is presented as an image plot, you have the freedom to define datasets manually and use our integrated plot digitizer tool to extract data from plots.
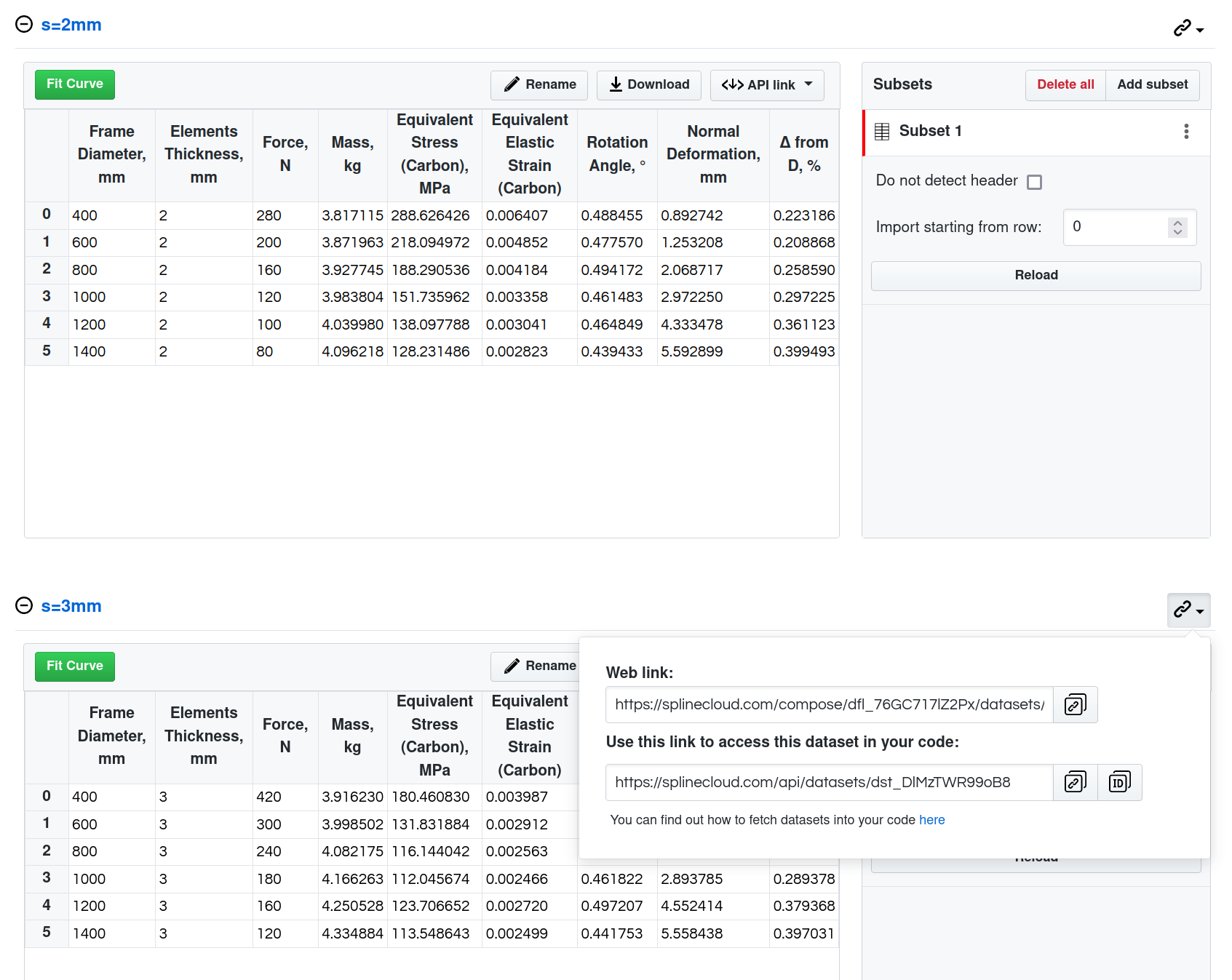
Spreadsheet Datasets
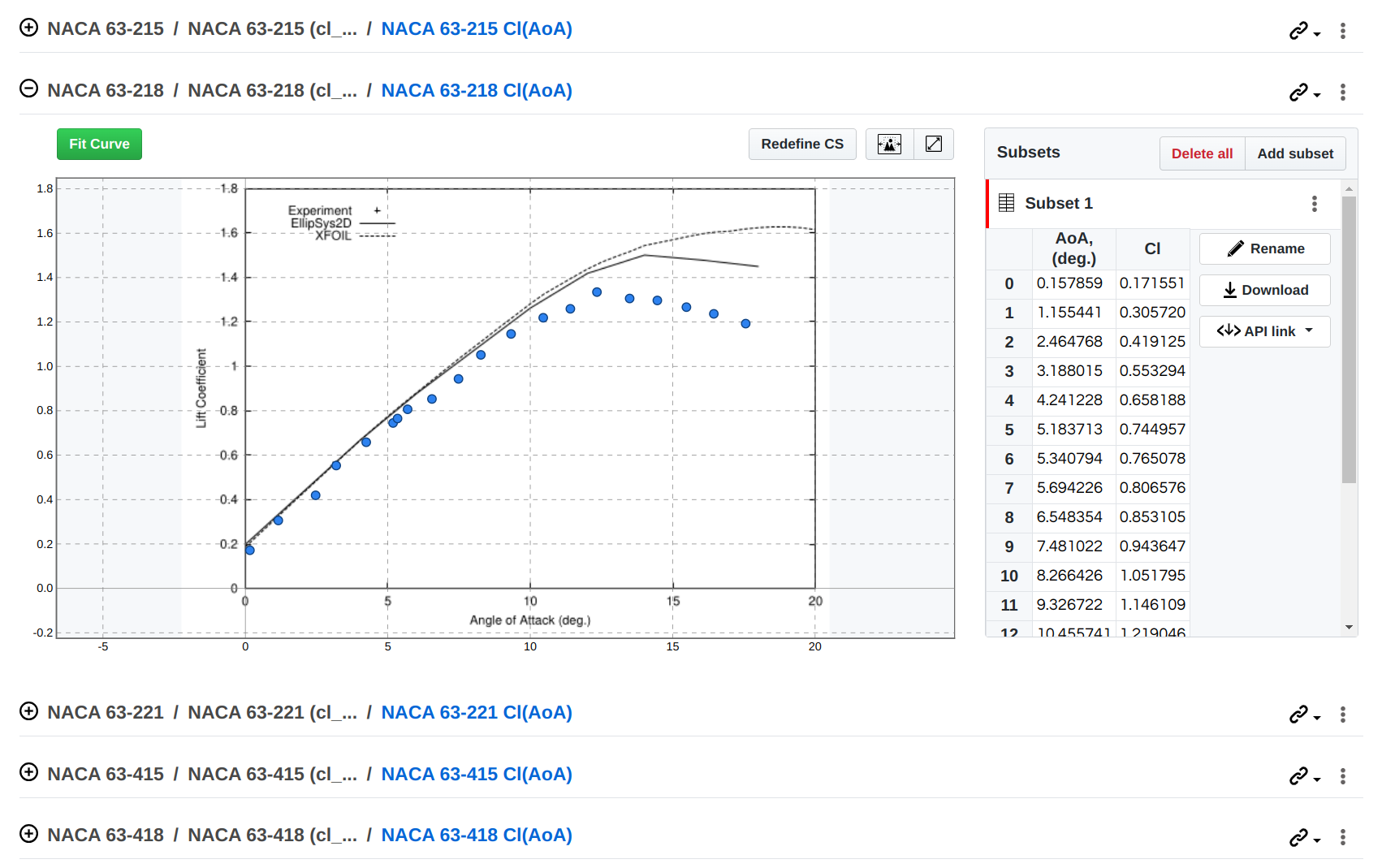
Digitized Image Datasets
Relations
Each data has something to say, and in most cases, it says that some variables exhibit a relation to another variable. To map these relations and turn them into reusable objects SplineCloud provides an interactive curve-fitting tool that allows you to find the best fit for your data in just a few clicks.
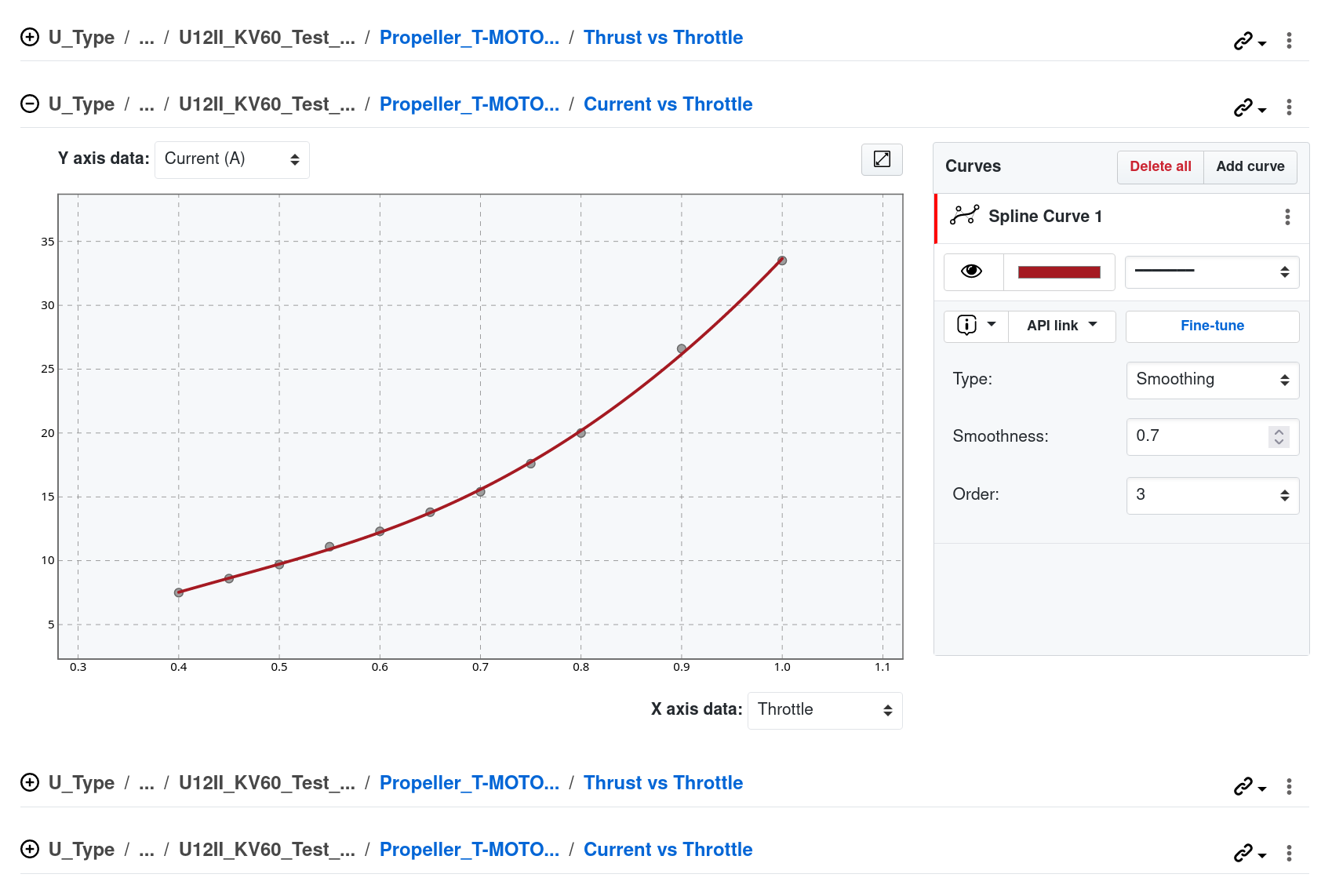
Functional Relations in Data
SplineCloud API
Standardized data and metadata representation together with open API facilitate seamless integration of data into your modeling environments and data processing workflows. All objects created on SplineCloud become accessible via SplineCloud API. We also provide free clients for Python and MATLAB that simplify access and reuse of data and relations in your code.
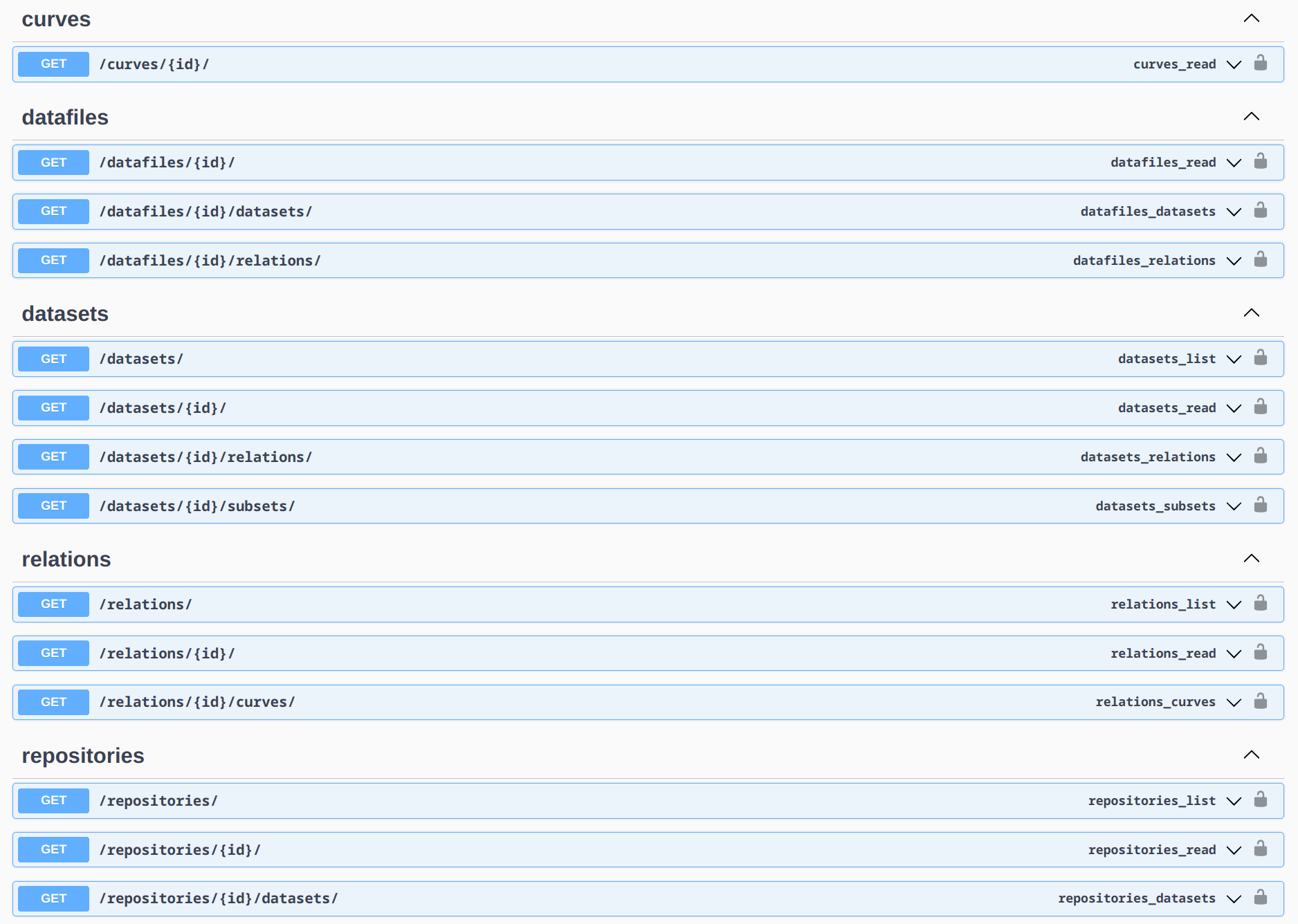
SplineCloud API Documentation
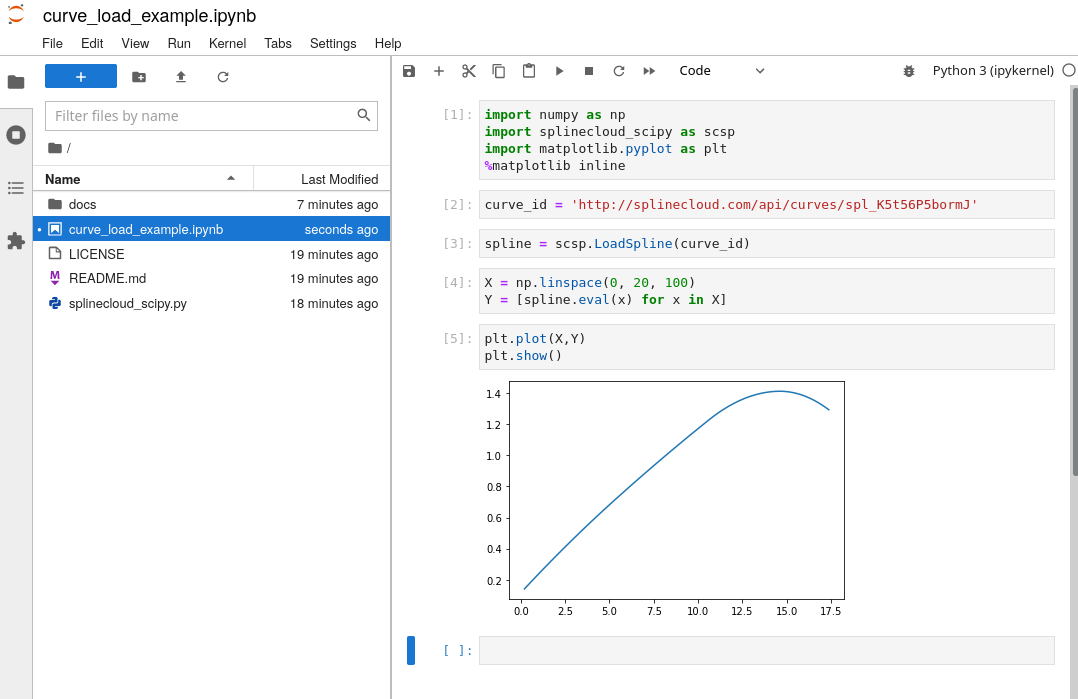
Curve loaded into Jupyter Notebook
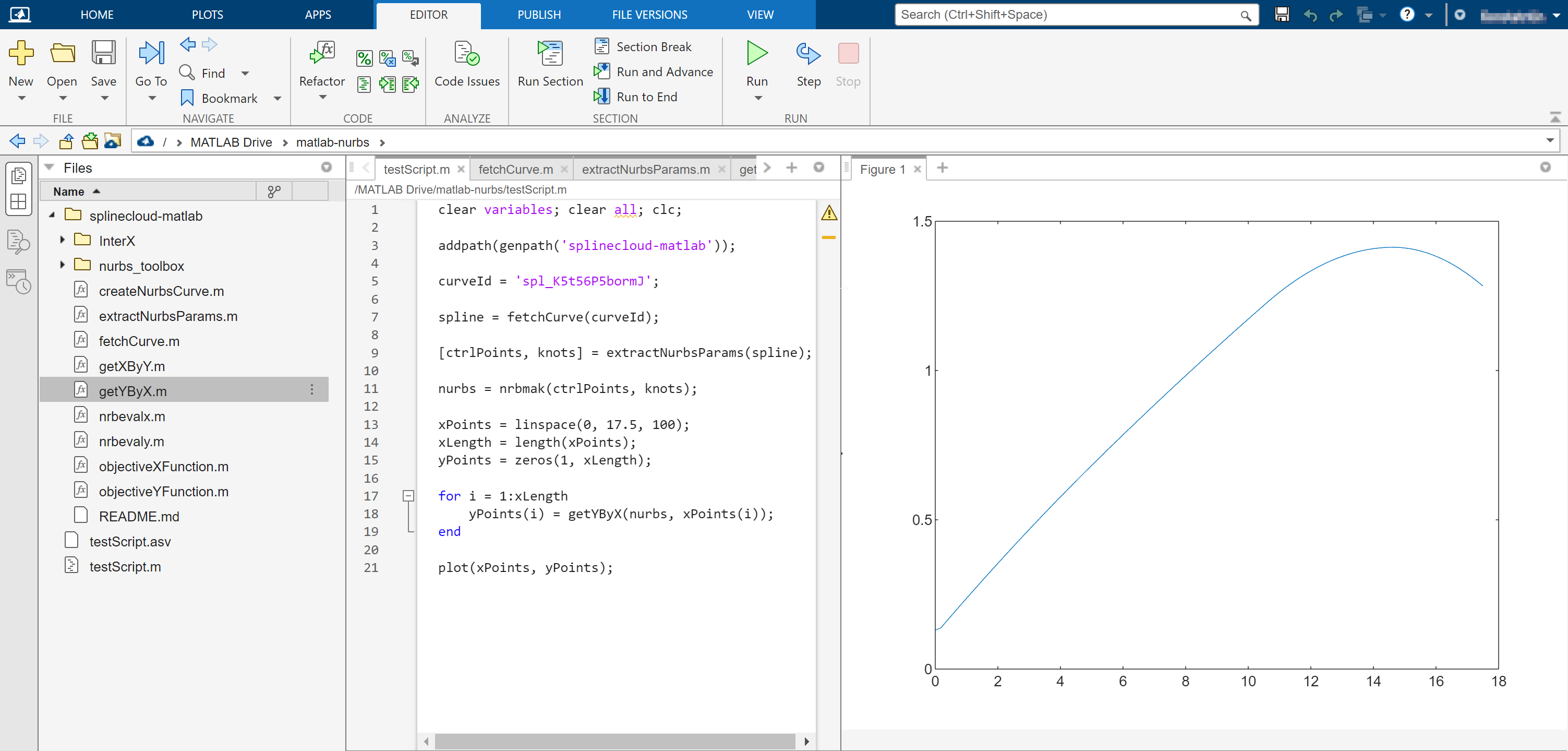
Curve loaded into MATLAB
Excited to become a member of our open community? Sign up for free now and start sharing your knowledge on SplineCloud!